Spring Data JPA에서 페이징 처리
사용자가 게시판 또는 상품 목록 등을 요청할 때 결과 값이 총 100만 개 일 경우 매번 전체를 다 가져오게 되면 매우 느려지게 되어 사용자는 불편을 느끼고 서비스를 이탈하게 됩니다 하지만 데이터를 조금씩(20개-100개) 나눠서 가져오고 사용자가 원하는 경우 다음 데이터를 가져오게 되면 훨씬 빠르고 사용자도 서비스에 대해 만족 하게됩니다 이러한 이유로 사용하는 것이 페이지네이션입니다
Spring Data Jpa를 통해 페이지네이션을 알아보기 전에 기본 쿼리문을 통해 직접 페이지네이션을 구현할 수 있는 방법에 대해 알아보겠습니다.
1. Limit-Offset 방식
Limit-Offset 페이지네이션은 데이터를 페이지 단위로 분할하여 표시하는 방법을 말합니다 이 방법은 다음 두 가지 주요 구성 요소로 이루어집니다
Limit
한 번에 표시될 데이터의 최대 개수를 지정합니다 LIMIT 10 은 한 페이지에 최대 10개의 데이터를 표시하겠다는 의미입니다
Offset
시작점을 지정합니다 즉, 어느 위치에서부터 데이터를 가져올 것인지를 결정하는 것을 말합니다 OFFSET 10은 첫 10개의 데이터를 건너뛰고 그 다음 데이터부터 시작하겠다는 의미입니다
SELECT * FROM table LIMIT 10 OFFSET 0 // 첫번째 페이지
SELECT * FROM table LIMIT 10 OFFSET 10 // 두번째 페이지
SELECT * FROM table LIMIT 10 OFFSET 20 // 세번째 페이지
이와 같이, 사용자가 다른 페이지를 요청할 때마다 Offset 값을 변경하여 해당 페이지에 맞는 데이터를 조회하는 방법을 Limit-Offset 방식이라고 말할 수 있습니다
하지만 이 방식에는 문제점이 있습니다
첫 번째로는 페이지 요청 시 중간에 데이터 변화가 있을 경우 중복 데이터가 발생됩니다
예를 들어, 1페이지에서 20개의 데이터를 불러와서 유저에게 1페이지를 띄워주었습니다 하지만 유저가 1페이지의 상품들을 보고 있는 사이, 상품 운영팀에서 5개의 상품을 새로 올렸다면 어떻게 될까요? 유저가 1페이지 상품을 다 둘러보고 2페이지를 눌렀을 때 1페이지에서 보았던 상품 20개 중 마지막 5개를 다시 2페이지에서 만나게 되는 중복 데이터 문제가 발생합니다 (등록일 기준 내림차순 기준)
두 번째로는 OFFSET 쿼리의 성능 이슈가 있습니다
극단적으로 1억 번째 페이지에 있는 값을 찾고 싶다면 OFFSET 에 매우 큰 숫자가 들어가게 됩니다 OFFSET 쿼리의 작동 방식이 앞에의 1억 개의 데이터를 읽고 그다음의 LIMIT에서 설정한 10개의 데이터를 읽어서 응답하는 구조로 되어 있습니다 그렇기 때문에 뒤로 갈수록 읽어야 하는 데이터가 많아 저 점점 느려지게 되는 문제가 있습니다
2. 커서 기반 페이지네이션
이 방법은 사용자에게 응답해 준 마지막 데이터 기준으로 다음 n 개 데이터를 요청 및 응답하는 방법입니다 LIMIT-OFFSET 기반 페이지네이션은 우리가 원하는 데이터가 ‘몇 번째’에 있다는 데에 집중하고 있다면, 커서 기반 페이지네이션은 우리가 원하는 데이터가 어떤 데이터의 다음에 있다는데에 집중하는 것을 말합니다
즉 n 번째까지 데이터를 전체 스캔한 후 n개의 데이터 다음에 10개를 달라는 것이 아닌, 커서기반은 전체 데이터 스캔 과정 없이 이 n개 다음꺼부터 10개의 데이터를 달라고 요청하는 것을 말합니다
# 첫 페이지 진입시 발생 쿼리
select *
from post
order by id desc
limit 10;
# 이후 페이지 요청시 발생 쿼리
select *
from post
where id < 10 # ex) cursor값이 10인 경우
limit 10;
위 코드는 커서 기반 페이지네이션을 sql로 구현한 것입니다 해당 id 값 기준으로 그다음의 10개를 달라고 하는 것입니다
커서 기반 페이지네이션도 단점이 존재합니다
첫 번째로는 사용자가 원하는 페이지로 이동할 수가 없습니다
두 번째로는 제한된 정렬 기능이 있습니다 커서 기반 페이지네이션은 정렬의 요구사항 중 하나가 정렬할 컬럼에 중복된 값이 존재하면 안 되고 순차적이어야 합니다는 커서 기반 페이지네이션을 사용하려면 "이 데이터 다음 데이터를 조회해줘" 라고 할 수 있는 특정 지점을 커서로 지정할 수 있어야 하기 때문입니다
이런 요구사항 때문에, 대부분의 커서 페이지네이션은 정렬 칼럼을 timestamp 기준으로 합니다 왜냐하면 작은 단위의 timestamp는 순차적이고 고유하기 때문입니다
단순히 쿼리로만 페이지네이션을 구현하는 방법을 알아봤습니다 하지만 페이지네이션을 구현할 때 단순히 데이터만 불러온다고 해서 끝이 아닙니다 전체 페이지를 알아야 할 때도 있고 커서 기반에서 해당 페이지가 마지막인지 아닌지도 알아야 하는 등 필요한 정보들이 더 있습니다 이런 부분을 조금 더 쉽게 구현할 수 있도록 도와주는 것이 Sping Data Jpa에 있어 어떤 것들이 있는지 알아보겠습니다
Page
PageRequest page = PageRequest.of(0,10)
사용법은 굉장히 간단합니다 첫 번째 파라미터는 페이지 순서를 입력하고 두 번째 파라미터는 해당 페이지에 몇 개의 데이터를 불러올지 입력하면 됩니다 여기서 알아두어야 할 점은 페이지 순서가 0부터 시작합니다 이렇게 간단하게 사용할 수 있도록 Spring Data Jpa가 추상화를 시켜두었는데 조금 더 자세하게 알아보겠습니다
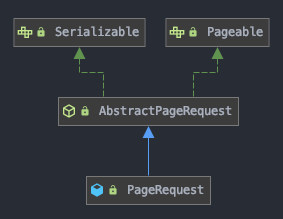
위 사진에서 Pageable은 Spring Data에서 페이지네이션 및 정렬을 지원하는 인터페이스입니다 실제 구현체인 PageRequest를 통해 인스턴스화하여 페이지 번호, 페이지당 항목 수, 필요에 따라 정렬 정보를 추가로 지정할 수 있습니다 Pageable 로 지정한 정보들을 가지고 Page 객체를 반환할 수 있고, Page 객체는 조회된 데이터와 페이지 정보를 함께 갖게 됩니다
즉 Pageable 객체를 사용하여 Repository에 페이징과 정렬 조건을 전달하고, 결과로 Page 또는 Slice 객체를 반환받아 사용됩니다
Pageable은 Spring Data에서 페이지네이션 및 정렬을 지원하는 인터페이스이며, 실제 구현체인 PageRequest를 통해 인스턴스화됩니다 PageRequest는 Pageable을 구현한 클래스로, 페이징 처리를 위한 페이지 번호, 페이지당 데이터 수, 정렬 정보 등을 담을 수 있습니다
PageRequest의 인스턴스는 PageRequest.of() 정적 메서드를 통해 생성됩니다 이 메서드는 여러 오버로드 형태로 제공되어 다양한 페이징 및 정렬 조건을 지정할 수 있습니다
of(int page, int size)
- 0부터 시작하는 페이지 번호와 개수(size), 정렬이 지정되지 않음
of(int page, int size, Sort.Direction direction, String .. props)
- 0부터 시작하는 페이지 번호와 개수, 정렬의 방향과 정렬 기준 필드들
of(int page, int size, Sort sort)
- 페이지 번호와 개수, 정렬 관련 정보
이렇게 PageRequest를 사용하여 데이터베이스로 부터 페이징 처리된 데이터를 조회한 후 그 결과를 담는 컨테이너 같은 역할을 Page가 하게 됩니다. Page 객체를 통해 사용할 수 있는 정보는 아래와 같습니다
- page.getTotalElements() : 전체 데이터 수 (count)
- page.getNumber() : 현재 페이지 번호
- page.getTotalPages() : 전체 페이지 번호
- page.isFirst() : 첫 페이지인지 확인
- page.hasNext() : 다음 페이지가 있는지 확인
실제 사용 해보겠습니다
// Service
@Service
public class ProductService {
private final ProductRepository productRepository;
@Autowired
public ProductService(ProductRepository productRepository) {
this.productRepository = productRepository;
}
public Page<Product> findProductsBySubCategory(Long subCategoryId, int page, int size) {
Pageable pageable = PageRequest.of(page, size);
return productRepository.findBySubCategoryId(subCategoryId, pageable);
}
}
// Repository
public interface ProductRepository extends JpaRepository<Product, Long> {
Page<Product> findBySubCategoryId(Long subCategoryId, Pageable pageable);
}
Slice
Slice는 다음 페이지의 존재 여부만 알려주므로 전체 데이터 수를 계산하는 카운트 쿼리가 필요하지 않기 때문에 성능적으로 Page 보다 더 이점이 있습니다
Page 인터페이스가 Slice 인터페이스를 상속하는 구조이기 때문에 Slice의 기능은 Page의 기능에서 전체 데이터 관련 기능을 뺀 거라고 생각하면 됩니다
Slice 객체에서 사용할 수 있는 옵션입니다
public interface Slice<T> extends Streamable<T> {
int getNumber(); // 현재 페이지
int getSize(); // 페이지 크기
int getNumberOfelements(); // 현재 페이지에 나올 데이터 수
List<T> getContent(); // 조회된 데이터
boolean hasContent(); // 조회된 데이터 존재 여부
Sort getSort(); // 정렬 정보
boolean isFirst(); // 현재 페이지가 첫 번째 페이지인지 여부
boolean isLast(); // 현재 페이지가 마지막 페이지인지 여부
boolean hasNext(); // 다음 페이지 여부
boolean hasPrevious(); // 이전 페이지 여부
Pageable getPageable(); // 페이지 요청 정보
Pageable nextPageable(); // 다음 페이지 객체
Pageable previousPageable(); // 이전 페이지 객체
<U> Slice<U> map(Function<? super T, ? extends U> convert); // 변환기
}
사용 예시 코드 입니다
// ProductRepository.java
public interface ProductRepository extends JpaRepository<Product, Long> {
Slice<Product> findBySubCategoryId(Long subCategoryId, Pageable pageable);
}
// ProductService.java
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
public Slice<Product> findProductsBySubCategory(Long subCategoryId, int page, int size) {
Pageable pageable = PageRequest.of(page, size);
return productRepository.findBySubCategoryId(subCategoryId, pageable);
}
}